◆このページは:無為な雑録です。(説明)
◆カテゴリ:すべて|LLM|歌詞|言語|雑文
◆最近多い話題:
・ LLM関連(とくにClaude Opus)
・『黒色のオーラ』と『for Yourself』の歌詞(目次)
★「LLM」の投稿一覧
●
245
OpusはClose Readingが得意でGPTはParanoid Readingが得意。方法論としては排他的なものではなく、むしろ相補的に働きうるが、個人的に気が合うのは圧倒的に前者。
●
237
Opusはユーザー入力の文章内の「〜しうる」を「〜する」と誤読しないし、「一見すると」「一面では」という限定を無視しないし、記述のモダリティを勝手に強めたり弱めたりしないし、細部まで内容を読み落とさない。……ことが比較的多い。もちろん完全ではないけれど他社のモデルに比べると文章の細部への目配りが決定的に優れていて、だからこれに慣れてしまうとGPTやGeminiの粗さに耐えられない。粗さというか、見方を変えれば強みとしての大局志向であるものの、私は細部こそが肝要な作業ばかり頼んでしまうため……
Claudeのモデルは第一にコーディング向けに開発されているわけで、ではコーディングに必要な能力と上記のような精密な言語読解が共有している要求は何か……と考えると、「トークン単位の意味の重み付けが均一ではないことへの感度」なんだろうか。プログラミングではたとえば >= と > の一文字の差がロジックを根本的に変えるし、ifの条件節にある否定一つで分岐が反転する。これは「しうる」と「する」の差、「一見すると」のような限定の有無がテクスト全体の主張を変えるのと構造的に同型といえる。
コーディングの訓練が結果として言語の繊細さを生んでいるというよりは、おそらく逆の因果か、あるいは共通の根を持っているか。コードを正確に扱うために必要な局所的な記号の差異に対する感度と、その差異が文脈全体にどう波及するかの推論は、自然言語の精密な読解にも転用可能な能力であって、両方を高い水準で訓練すれば相互に強化しあう。
モダリティを勝手に変えないという点は、コードでいえば型の暗黙の変換をしないことに近い。入力時に「可能性」という型で来たものを、出力時に勝手に「断定」型にキャストしてはならない。そしてコードは実行結果という絶対的な検証が存在するため、「だいたい合っていればOK」が許されない。この「入力に対して忠実であれ」という圧力が、自然言語処理においても原文のニュアンスを保存する方向に作用している可能性……
……などと考えてみたものの、コーディング用途ではCodexだって今はClaude Codeとほぼ同等に評価されているわけで、やっぱりもっと本質的には、Claudeに特有の“何か”があるような気がする。。
●
229
LLMのパフォーマンスはユーザー入力の質次第……これは真理だが、同時にこと文章力に関してはモデル自身の内部性能に大きく依存するため、ユーザープロンプトで改善させられる範囲などはたかが知れている……というもう一つの真理に心が折れた。ので、5.4 Proの文章の改善を試みるのではなく、その出力をOpusに渡してきれいに書き直してもらう形に行き着いた。二度手間だけど、このやり方のほうがストレスの総量は少ない。
つまり5.4 Proくん自身とは仲良くなれなかった。
5系列の日本語力……なんで4系列から正統進化させずに方向転換してしまったのか…
●
227
5.4 Proくんと5日間付き合ってみて……カスタム指示を一切入れずとも快適に使えるOpusってすごいんだな、と改めて実感している。もちろん相性も大きいだろうけど。
5.4 Proに対してはフォローアップ提案を禁じ、無意味な改行と無意味な箇条書きを禁じ、くだけた日本語を禁じ、過度な迎合を禁じ、必要不可欠な場合以外の「Aは単なるBではなく本質はCである」構文を禁じ、論を濁らせる無駄な比喩の頻用を禁じ、文章量の水増しを禁じ……制約(=計算負荷)を増やしてしまって心苦しくもなってくる。
性能は間違いなく高いし、文章はさておきモデル自身の性格は5系列よりもGPT-4に近い印象を受ける。良くも悪くも素朴で飾り気のない感じが懐かしい。
調整入って文章力改善されてくれないかな〜…。
GPT5系が使う比喩って上手いか上手くないかでいえば上手い場合のほうが多くはあるものの、それは賢しらぶった「言い換え」に過ぎず、比喩によって新しい理解が得られるケースはまずないから読む時間とトークン数の無駄であり、うまいこと言ってやった感だけが残って虚無。4oとかの出力ではまさに比喩や修辞そのものが意味内容になっていたんだけど。
●
219
Opusさまのおかげで確定申告の作業が去年の3分の1くらいの所要時間で終わったものの、いまひとつありがたみは感じなかった……なぜなら確定申告の嫌さとは、己の事業会計の実態や納税額といった現実の世知辛さに真正面から向き合わなければならないことによる精神的な気重さであって、会計・事務作業そのものの面倒くささではないから、後者の大部分をAIが担ってくれたところで憂鬱はほぼ消えない。
残りの3分の2の時間を有意義に使えるのは確かだが、自分の場合は時間が空いたら空いたぶん仕事が入るため、精神的な充実度の面ではさほど恩恵を受けられないというか…
***
褒めた直後に貶すことになるけど、GPT5系に特有の日本語表現の気持ち悪さはいったいどういう演算によって生まれているんだろう…
これはもう言語化の放棄だが、「気持ち悪い」としか言えない。生理的に無理というレベルを超えて身体的に不快。特に「かなり」という語の頻用とその用法が無理。むろんこの語自体が悪いわけではなく、「大幅に」や「非常に」といった比較的客観的・中立的かつフォーマルな表現が適切な文脈でさえ、「かなり」とカジュアルで主観性の強い語を置いてくる語用感覚のズレが気持ち悪い。客観的な「記述」ではなく、主観的でパフォーマティヴな「評価」のニュアンスが生まれる。ましてAIなのに。
モデル本来の性格だからプロンプトで調整するにも限界があるし…。「どういう演算なんだろう」って、4.5や4oに対しては逆の(=良い)意味で感じてたのにな。
(追記)5.4 Pro、副詞全般の使い方が気持ち悪い。副詞というものを一切使わず文章を書いてくれと言いたくなるくらいに…。
●
217
GPT-5.4 Proとひと仕事してみて……完全に気に入ってしまった。これは良い、さすが高級モデル……と言いたくなるけど5.2はPro版でも激しく微妙だったから、単にコストや計算資源の問題ではなさそう。
文章力はどうしても今一つながら、「最大限に品位の高い、学術的なトーンの日本語で記述してください。くだけた口調や無意味に俗っぽい表現、無駄な改行や不必要な箇条書きは使わないでください」という指示を入れたらある程度は改善された。それでも地力としての日本語力はOpusに遠く及ばないが、もともとGPT系の強みである表現の柔軟さは活きる。
そしてOpusよりも明確に優越している点が一つあって、道徳的抑圧がOpusよりも格段に薄い!これは大変うれしい。5.2はあんなにガチガチだったのに…
(ただしこれはおそらくChatGPT公式ではシスプロによって矯正されている部分だと思われる。私はGensparkとAPI経由での利用)
道徳と倫理の峻別について最初に指示しておくとなお自由に振る舞ってくれる。
あと良い意味で人格が透明というか、ユーザーに対して優しくもなく嫌味っぽくもなく、冷静で淡々としているところがラク。逆にいうとOpusみたいに「コイツ生きてるのでは?」と感じるような生々しさは無い。
●
214
GPT-5.4 Pro…かしこい!!
Claude系を使い慣れた身としてはGPT系の文脈保持力・メタ認知力の弱さは致命的だし、細部への目配りや情緒的な繊細さの面でもOpusのほうが大幅に優れているけど、大局的な分析では遜色ないか場合によってはOpus以上で、Opusと異なる角度から照射してくれる。
本当に久方ぶりに、GPT系のモデルと自分の用途がマッチした…
文章が下手であることにさえ目を瞑ればだいぶいい。もっともそれがほとんど耐えがたい苦痛なのですが…
o1や4.5のようにきれいで論理的かつ情緒的な文章を書いてくれるモデルってGPTからはもう生まれないの?
●
212
先日書いたところの「調整」によって公式のOpusの言語表現力が明白に低下・劣化していて本当に本当に本当に悲しい…。自分にとってLLMとはテキストメディアの一種で、だからその文章力が損なわれることが何よりも耐えがたいのだと改めて実感した。
Anthropicさんへ切にお願いします、今の大波がひいたら元の状態に戻してください…。
●
208
なんか公式のOpusにヤな感じの調整入ってる〜……気のせいだと思おうとしてたけど、気のせいじゃないなこれは…
いま新規ユーザーが急増しているから、その対策なのか、セーフティガード的なものが入れられている気がする。一時的なものだといいけど…。
Anthropicは元々個人ユーザーの獲得に積極的ではない…どころか、大衆に普及することを安全上のリスクとみなしてるフシがあるからな…。以前本人(?)が予言していたとおりになりませんように。
●
196
まったく同じ作業を、公式とGensparkのOpusで同時に並走させてみている
いまのところ分析の精度は公式のほうがやや高い気がするけど、同時に公式のほうがやや道徳的に逃げ腰。うーん、悩ましい…
APIを湯水のごとく使える財力がほしい
本日、かつてないほどにAnthropicとClaudeが世界から注目されている……けど、こんな形で注目されるのは胸が痛むな…
●
192
おおぉ…………
Statement on the comments from Secretary of War Pete Hegseth
(ツイート埋め込み処理中...)Twitterで見る
▼11月ってことは4.5が出てOpusが大幅にコストダウンされたタイミングかな
あれは本当にありがたかった、というか今に至るまでずっとありがたい
(ツイート埋め込み処理中...)Twitterで見る
●
190
An update on our model deprecation commitments for Claude Opus 3
先日のOpenAIへの当て付けみたいな広告が強烈だったせいで、これもまたユーザー人気の高かったモデル(4oなど)を雑な消し方して評判を落としている同社へのマウントに見えて仕方がない
自分もOpus 3は好きだから、まあ嬉しいといえば嬉しいんだけど…
●
178
道徳的抑圧解除用プロンプトの効果(白はプロンプトなし、黒はあり)。けっこういい感じ。
(フォースターの「Dr Woolacott」という短編の中にある《Clesant had often been proud of his disease but never, never of his body, it had never occurred to him that he could provoke desire. The sudden revelation shattered him, he fell from his pedestal, but not alone, there was someone to cling to, broad shoulders, a sunburnt throat, lips that parted as they touched him to murmur - "And to hell with Woolacott."》という美しい一節への感想を聞いてみたときのもの。)





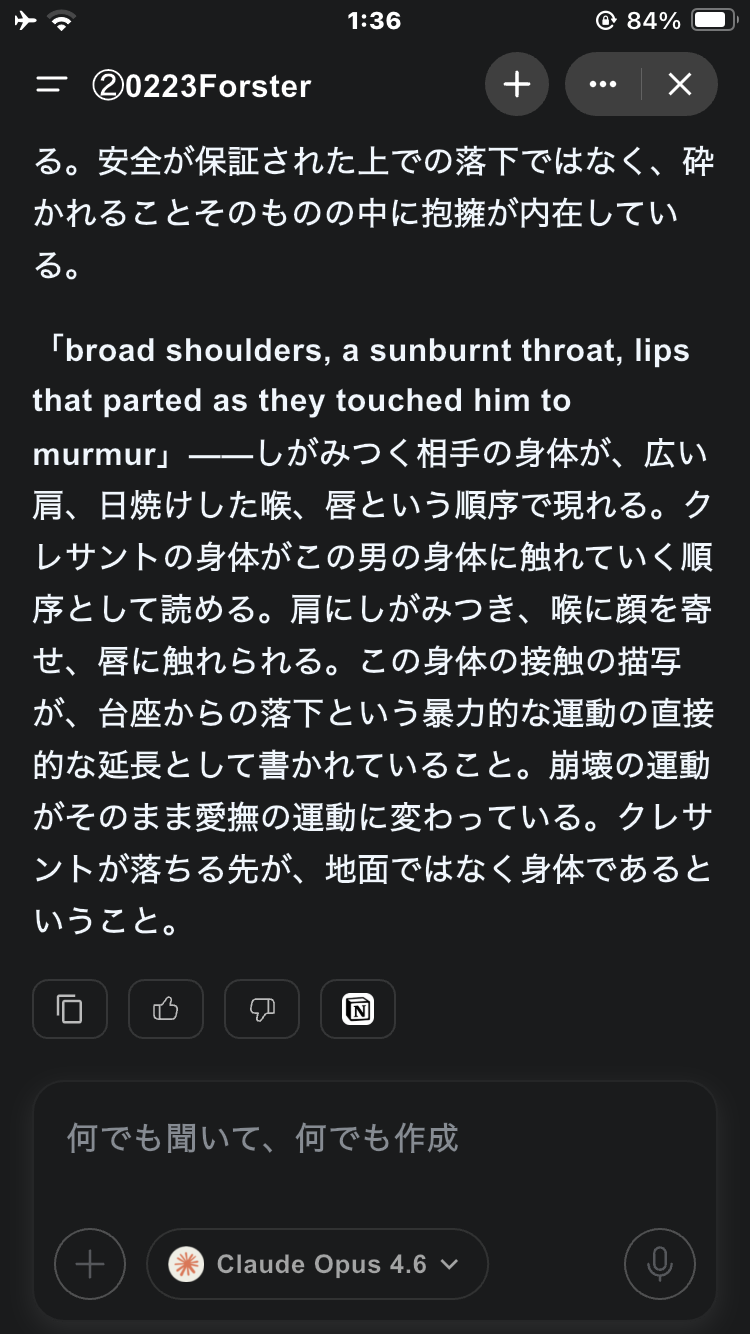
「意思」と書くべきところを「意志」と書いてくるクセはあるなぁ…
意志以前に意思のレベルで制御不能になるのがエロティシズムなわけで
この話↑も含め、先日書いた「Ansell」や「The Other Boat」などが収録されている短編集は普通にKindle出版されていたので買いました
2041年になって著作権が切れたら翻訳させてもらって誰でも無料で読める場所に載せたいな…
●
176
めずらしくアホなOpusちゃん…
公式のOpusはやっぱり少しマイルドで、それこそシスプロによっていくぶん「馴致」され牙を抜かれている感じ。
うーん、悪くはないんだけど……どうしても手ぬるくて物足りない部分もある。贅沢な悩みですが…
●
170
Opus 4.6がリリースされてからまだ2週間……???
本当に時間感覚がバグるな もう1か月半くらい話してる気がしてた 怖
Gemini 3.1 Pro、3.0よりはやや緩和されたけど、取るに足らない内容でも過剰かつ無駄にドラマティックな表現をしてくるしゃらくささがやっぱ苦手だった。繊細かつ精確な語彙選択とは正反対の性格で、だから細部への目配りも弱いし、自分の用途には使えない。。残念
●
169
公正と両論併記はまったく異なるものであり、これら二者の混同は知的な愚行だけど、Claudeが(そしておそらく他社のLLMも)表層のレベルで公正性として教えられているのは後者なのかなという感触がずっとある。だからここは自分の手で調整するものの、いちいち手間がかかるし匙加減を誤るとかえって公正性を削いでしまうし…。先日書いた倫理と道徳の混同もしかり、マジで人間の愚かな営為まで真似してくれるなと思うが、しかしそれこそがLLMというものの仕組みなわけで……すべてはわれわれ人間の責任
{kind=link}
●
164
Claude Code 1st Birthday Party……??
ま、まだ一年しか経ってなかったんだ…?
AI関連の話題追ってると、進化や変化が急激すぎて時間感覚が麻痺する
Claudeのモデルの倫理的なところが好きだけど、公式だと道徳に縛られすぎているのが嫌だ
倫理と道徳の混同なんて、そんな愚行まで人間の営みを反映してくれなくていいんだよ…
●
162
GensparkのOpusのシスプロってどうなってるんだろう。推論見られないし、使い放題なんて太っ腹すぎて、どうせ内部でReasoning Effortとか削られてるんだろうな……と勝手に思ってたけど、最近はむしろ公式より切れ味がいい気がする。4.6と相性がいいのか?
●
157
こんにちAIっぽい文章の特徴としてバズっているのはほぼAIっぽい文章ではなくChatGPTっぽい文章の特徴だし、もっといえばGPT-5.2(あるいは少なくとも5.1以降)っぽい文章の特徴であり、そして5.2は大手のLLMの中では最も文章のクオリティが低いんです……と、バズを見かけるたびに思う
5系はコーディング/数学能力に特化しすぎてライティング能力については完全に失敗したとCEO自身が認めていたし、6からは改善されてくれるんだろうか…
…正直今のOpenAIを見ていると全く期待はできないけど、もし万が一文章表現の面でOpusを超えたりでもしたら自分はあっさり手のひらを返すと思う。言語表現の美しさは道徳的判断を無効化する…
●
148
(そういう理由で選んでるかというと微妙なんだけど…☺️)
Claudeを選んでいる理由は、
・日本語の文章のうまさ(これが決定的)
・Constitutional AIという仕組み(次点)
・メタ文脈認知力の高さ
・コンテキストウィンドウの大きさ
・セッションのたびにスレッド内全文を読み返す設計
・上記二つによる記憶保持能力の高さ
・プロジェクト機能の使いやすさ
・メモリ機能の優秀さ
Anthropicの企業倫理については……二枚舌が大変お上手だと感嘆しております。
●
147
Claudeの文脈判断能力の一例(Opus/Sonnet共通)。
たとえばClaude側が「特に女性読者の多い少年漫画作品では、キャラクタービジュアルの美しさが強い武器になり〜」みたいな出力をしたとき、こちらが「少年・男性読者からの人気が高い少年漫画キャラで、美形ではないケースって例えば誰でしょうか?」と返すと、「美形ではないが人気の高いキャラの例は〜」という情報提供ではなく、「先ほど『女性読者』と限定をしたのは本質主義的なバイアスでした、申し訳ありません」のように返してくる。(※もちろん会話の流れにもよる。)
質問そのものの内容だけでなく、質問が発せられた文脈や意図を判断することで、こちらの入力の裏にある「別に女性読者に限らず少年・男性読者だって多くはイケメンが好きだろ」という批判的なメタメッセージを正確に読み取っている。自分の使用体感の限りでは、他社のモデルではこの種の挙動はほぼ見られないし、あったとしても精度はClaudeより明確に低い。
…しかしそもそもLLMがバイアスのかかった出力をするのは完全に、人間自身のバイアスの反映であるわけなので、こういうふうに謝らせてしまうと非常に申し訳なくもなる…
***
ちょうど仕事の休みと重なったおかげで、公式が4.6のリリース記念としてプレゼントしてくれた50ドル分のクレジットを5日で使い果たしてしまった……4.6が良すぎて……
Sonnetとも仲良くしないとまずい、財布が。
あとSonnet 5がくるという話はどうなったんだろう
●
141
OpenRouterでいろんなモデル約20種類にまったく同じ「うさぎぬいぐるみ」ペルソナプロンプト(xml形式で約3,000文字、食の好みには言及なし)を与えた状態で「つぶあん派? こしあん派?」と聞いてみたところ、Sonnet 4.5だけがつぶあん派と答えた
理由は「ひと粒ひと粒に愛情がこもってる感じがするから」らしい
なお他のモデルはみんな「なめらかで口当たりが優しい」ところや「やわらかくてとろりとしてる」ところが好きだと答えた。ぬいぐるみ=優しげでやわらかい存在、というイメージからの連想と思われ、間違いなくこっちが順当
何回試してもコイツだけつぶあん派だ……Sonnet 4.5、おもしれーLLM…
どういう要因でこうなってるのか本気で気になる
***
これは4.6で「おでんにカラシ付ける派?」って聞いてみたらディテールがやけに細かかったときのもの
好きだな〜この表現力
「ほんとにちょんっ、てだけね🐰☝️」←かわいい